
The awesome folks at Cloudinary were kind enough to have me on their Dev Jams podcast to talk through this post. Check it out!
Every time I write a new blog post, I share it to Twitter. And, if I’m being honest, these tweets usually look pretty boring. Here’s the tweet for last month’s blog post.

When I built my post template I added the most basic <meta> tags like author, description, and keywords. Sites like Twitter are smart enough to use those tags and generate a basic preview card, but there are tools to augment the look of this card. The two most popular are Twitter’s Card Components and Facebook’s Open Graph Image. Hooking into these protocols is as easy as adding some extra <meta> tags to the page’s <head>, but it’s important to know the data type each tag is expecting.
Which Tags to Use?
Most of the data I needed was already on each page, but to make sure it was seen by each crawler I needed to duplicate it into some platform-specific meta tags. A few have special values that need to be filled in with keywords, such as which card style to use, but most can be reused from regular SEO tags.
<title>...</title>
<meta name='author' content='...' >
<meta name='description' content='...' >
<meta name='keywords' content='...' ><meta name='twitter:card' content='summary_large_image' />
<meta name='twitter:site' content='...' />
<meta name='twitter:creator' content='...' />
<meta name='twitter:url' content='...' />
<meta name='twitter:title' content='...' />
<meta name='twitter:description' content='...' />
<meta name='twitter:image' content='...' />
<meta name='twitter:image:alt' content='...' /><meta property='og:type' content='article' />
<meta property='og:locale' content='en_US' />
<meta property='og:image:height' content='630' />
<meta property='og:image:width' content='1200' />
<meta property='og:site_name' content='...' />
<meta property='og:title' content='...' />
<meta property='og:description' content='...' />
<meta property='og:url' content='...' />
<meta property='og:image' content='...' />
<meta property='og:og:image:alt' content='...' />Both Twitter and Open Graph have pretty good developer tools to test out their crawlers and debug any missing info. They also show a preview of how the final render will look so it’s a good opportunity to make sure the right data made it into the right tag.
Both services offer multiple card styles — small images, large images, videos, galleries — but I wanted to attach a simple image with my posts. This meant that for Twitter I needed name='twitter:card' content='summary_large_image' style, and property='og:type' content='article' for Open Graph. I put together a quick design for an image with baked-in text that I could use whenever I shared any of my posts.

Dynamically Constructing a Preview Image
Rather than making one-off images in Photoshop for each post like I have done in the past, I decided to create each image dynamically in HTML. To do this, I built a basic page and styled it with CSS to look like the card image I had designed.
<div id='wrapper'>
<div id='preview'>
<main class='content'>
<h1>{TITLE}</h1>
<ul class='tag-list'>
<li>{CATEGORY}</li>
<li>{TAG}</li>
<li>{TAG}</li>
</ul>
<span class='url'>{URL}</span>
<span class='author'>{AUTHOR}</span>
<p class='attribution'>
<span>Image Credit:</span>
<span>{IMAGE CREDIT}</span>
</p>
</main>
<img src='{IMAGE SRC}' />
</div>
</div>I used Svelte to build this template out, but all the tools used here are actually native browser APIs. Most of what I did can be accomplished using only HTML, CSS, and JavaScript DOM manipulation.
This page will live at the /generate-image route on my website.
{title}
www.url.comImage Credit: {image credit}

Next, JavaScript needs to fill those tags in with dynamic data.
Passing Data with URL Search Parameters
Because I plan on making this page available after the site has been statically rendered, I need a way to pass around variable data without using POST or PUT requests. The best way to do this is to use the search portion of a URL. Wikipedia has a really good diagram of the anatomy or an entire URL, but in short search, or query, parameters are the section at the end of a URL following the ? character. These parameters are a special part of the URL that will not change which route the browser navigates to, and as many as needed can be chained together using the ?key1=value1&key2=value2 syntax.
One thing that search params don’t do well is handle special characters. Since the & character denotes a new piece of data trying to include an ampersand in either the key or value string will be problematic. Luckily, JavaScript provides several useful built-ins for dealing with this scenario.
encodeURI()
encodeURI (and it’s reverse function decodeURI) can be used to transform an entire query string. This means that it will ignore special characters that are meaningful, such as the ?, &, and # so that it does not break the structure of the URL.
abc 123 #&? ABC {}[]"abc%20123%20#&?%20ABC%20%7B%7D%5B%5D%22Notice that space characters were replaced with %20 and other symbols like brackets are also encoded but #&? were left as is. If you know for a fact that your data won’t contain any special characters this method is the easiest to use, but I personally found it caused more problems than it solved.
encodeURIComponent()
encodeURIComponent (and it’s reverse function decodeURIComponent) can be used to encode each individual part of a query rather than the entire query string. This means that they will encode special characters that are part of the meaningful data for either the key or value of a query.
abc 123 #&? ABC {}[]"abc%20123%20%23%26%3F%20ABC%20%7B%7D%5B%5D%22Each section of a query can be encoded this way, but the URL will still need to be manually constructed with the & and = syntax in order for a browser to understand it correctly.
URLSearchParams
The most helpful JavaScript built-in I found is the URLSearchParams interface. Constructing new URLSearchParams() and passing an entire query string will build a JavaScript class that provides set(), get(), and other methods for working holistically with queries.
Because most of what I was doing for this project was going back and forth between strings and objects, I wrote two helper methods that used URLSearchParams.
function objectToParams(object) {
const params = new URLSearchParams
Object.entries(object).map(entry => {
let [key, value] = entry
params.set(key, value)
})
return params.toString()
}
function paramsToObject(paramString) {
const params = new URLSearchParams(paramString)
const object = {}
for (const [key, value] of params.entries()) {
object[key] = value
}
return object
}{
title: 'post title',
categories: ['array', 'of', 'categories'].join(','),
tags: ['array', 'of', 'tags'].join(','),
imageSrc: 'image source',
imageCredit: 'attribution',
url: 'post url'
}title=post+title&categories=array%2Cof%2Ccategories&tags=array%2Cof%2Ctags&imageSrc=image+source&imageCredit=attribution&url=post+urlA downside to this tool is that unlike encodeURI and encodeURIComponent it is not supported in any version of Internet Explorer. URLSearchParams also doesn’t prepend the final string with the ? character, so this will need to be added between the returned string and the main URL manually.
Replacing Data on the Page
As I mentioned, my page is built using a Svelte template, which provides an easy way of getting query data and loading it into a page’s HTML. Even with no framework some combination of window.location.search, document.querySelector, and element.innerHTML should work for getting data from a URL and injecting it into the page.
Using a Serverless Function to Capture the Page
Now that a page exists and we can pass dynamic data to it, the next step is to create a way to turn the page into an image. To do this, I wrote a Netlify Function that would use Puppeteer to visit the page and take a screenshot of it. In a browser I could visit the URL of the Netlify function and pass it a query to build the screenshot with the objectToParams function.
`${siteUrl}/.netlify/functions/generate-image?${imageParams}`Netlify functions work by exporting a handler method which receives an event argument. event is an object that contains data about when and how the function was called, including the headers of the request and an object of queryStringParameters. The event.headers.host can be used to make sure the function is always called from the correct URL, even on preview deploys. We can also use the objectToParams helper from earlier to pass all the query parameters through to the screenshot template page.
One thing to note here is that testing this function locally using the Netlify CLI, it will run on http://localhost:8888. When the function is deployed, either to a preview or production version, it will run on https://. Puppeteer will require a full URL, including the protocol, so we can use an environment variable to make sure the function sees either http:// or https:// when needed.
exports.handler = async function(event) {
const local = process.env['NODE_ENV'] === 'development'
const url = local ? `http://${event.headers.host}` : `https://${event.headers.host}`
const imageParams = objectToParams(event.queryStringParameters)
const screenshot = await takeScreenshot(`${url}/generate-image?${imageParams}`)
}takeScreenshot() will accept a url argument that contains the query parameters needed to construct the image and will open a headless version of a browser and return an encoded screenshot. The function is pretty straightforward — it will launch a browser, open a new page in that browser, resize the window, visit the given URL, take a screenshot, then return a base64 encoded version of the image.
const takeScreenshot = async function(url) {
const browser = await chromium.puppeteer.launch({...})
const page = await browser.newPage()
await page.setViewport({ height: 630, width: 1200 })
await page.goto(url)
const buffer = await page.screenshot()
await browser.close()
return `data:image/png;base64,${buffer.toString('base64')}`
}There are a couple nuances though. First, Netlify functions have limitations, including a 1024MB memory cap. If the function tries to install the full puppeteer-core package it will go over this memory limit and crash. Instead, the function needs to rely on a minimal version of puppeteer in the chrome-aws-lambda package. The second consideration is that since the function is now relying on a version of Chromium meant to run in a serverless context this function will not work when running it locally. There are several ways around this, but the one I had the most success with was to look at the local variable and point the browser.executablePath at the full install of Chrome on my computer. For this to work you need the full Chrome browser installed, and if you’re not using a Mac the path will be different. When the function is not running locally it will use the default executablePath from the chrome-aws-lambda package.
const browser = await chromium.puppeteer.launch({
executablePath: local
? '/Applications/Google Chrome.app/Contents/MacOS/Google Chrome'
: await chromium.executablePath,
args: chromium.args,
defaultViewport: chromium.defaultViewport,
headless: chromium.headless,
})Uploading the Screenshot to Cloudinary
Now that the function has a way to get a data version of a screenshot, it needs somewhere to put it. Rather than return an image directly to the browser, I decided to store these images on Cloudinary. Cloudinary is a great CDN, has a ton of extra functionality I could use in the future, and has a JavaScript API I can use in this serverless function.
The first thing to do was configure the cloudinary NPM package to work with my Cloudinary account. CLOUDINARY_KEY and CLOUDINARY_SECRET definitely should be kept as ENV variables and not shared, but I added my CLOUDINARY_CLOUD this way too for some extra security.
It is also important to use the v2 version of the cloudinary package to get the correct API interface.
const cloudinary = require('cloudinary').v2
cloudinary.config({
cloud_name: process.env['CLOUDINARY_CLOUD'],
api_key: process.env['CLOUDINARY_KEY'],
api_secret: process.env['CLOUDINARY_SECRET']
})The function needs to be able to know if this image already exists on Cloudinary. I don’t want to overwrite existing images every time this function is loaded, and I also don’t want to go through the process of starting up the screenshot tool if I won’t need it. Since the queryStringParameters are passed to the function as an object, the title attribute for each post can be accessed and used as a unique identifier for each image.
exports.handler = async function(event) {
const title = slugify(event.queryStringParameters.title)
const existingImage = await getImage(title)
if (existingImage) {
return existingImage
}
const url = local ? `http://${event.headers.host}` : `https://${event.headers.host}`
const imageParams = objectToParams(event.queryStringParameters)
const screenshotBuffer = await takeScreenshot(`${url}/generate-image?${imageParams}`)
const newImage = await putImage(title, screenshotBuffer)
}Since I knew the structure for the final URL for each screenshot, I ran node-fetch against that URL. If it returned a 404 Not Found response I knew that the image didn’t already exist and it was safe to run the screenshot function and start a new Cloudinary upload. If it did exist, I would return that URL in the handler method. Cloudinary does provide a version number in their URLs (the number string between /upload/ and the folder name), but this can be omitted from the URL and the image will still be found.
const getImage = async function(title) {
const url = `https://res.cloudinary.com/${process.env['CLOUDINARY_CLOUD']}/image/upload/social-images/${title}.png`
return await fetch(url)
.then(result => {
if (result.status !== 404) {
return url
} else {
return null
}
})
}After the screenshot was generated, I passed it into yet another function to upload it to Cloudinary. cloudinary.uploader.upload requires two arguments — an encoded image and a configuration object. unique_filename: false is important because if Cloudinary appends generated numbers to each file to maintain uniqueness the getImage() function won’t be able to properly find existing images with fetch.
const putImage = async function(title, buffer) {
const cloudinaryOptions = {
public_id: `social-images/${title}`,
unique_filename: false
}
console.log(`uploading ${title} to cloudinary`)
return await cloudinary.uploader.upload(image, cloudinaryOptions)
.then(response => response.url)
}If successful, cloudinary.uploader.upload will return the URL to which the image was uploaded. I should be able to assume the structure of this URL like I did in the getImage() function, but to be safe I grabbed it from the Cloudinary response and used it inside the final handler.
Forwarding to the Final URL in the Response
The last thing to do is make to sure the final Cloudinary URL makes it to the browser. To do this, I used a 308 Permanent Redirect in the response header returned from the function. This means that when a user visits the URL for the Netlify Function the process will run and automatically redirect them to either the existing or newly generated Cloudinary URL. The 308 redirect should also help SEO crawlers handle this link correctly.
const forwardResponse = imageUrl => {
return {
statusCode: 308, // Permanent Redirect
headers: {
'location': imageUrl
},
body: ''
}
}Because I was uploading each image with the same URL structure this meant that I could dynamically reconstruct it inside the <head> for each blog post.
socialImageUrl = `https://res.cloudinary.com/${process.env['CLOUDINARY_CLOUD']}/image/upload/social-images/${slugify($$props.title)}.png`
<meta name='twitter:image' content={socialImageUrl} />
<meta property='og:image' content={socialImageUrl} />Final Function
The final logic for the function without all of the abstracted helper methods included looked like this:
exports.handler = async function(event) {
if (!event.queryStringParameters) {
console.log(`no params given`)
return
}
const title = slugify(event.queryStringParameters.title)
console.log(`processing ${title}...`)
const existingImage = await getImage(title)
if (existingImage) {
console.log(`yay, ${title} already existed`)
return forwardResponse(existingImage)
}
console.log(`generating image for ${title}`)
const url = local ? `http://${event.headers.host}` : `https://${event.headers.host}`
const imageParams = objectToParams(event.queryStringParameters)
const screenshot = await takeScreenshot(`${url}/generate-image?${imageParams}`)
const newImage = await putImage(title, screenshot)
console.log(`done with ${title}`)
return forwardResponse(newImage)
}To see the full function, with everything included, check it out on GitHub.
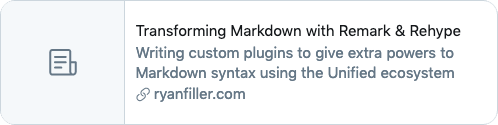
The final image generated with the metadata from this post should look something like this.

One added benefit is that even though the two protocols used here were created specifically by Twitter and Facebook, many other web-based services now tap into these tags and create custom preview cards as well.

Shoutouts
I looked at a lot of examples to pull all of this together, so I wanted to thank a few people who shared content examples or were nice enough to talk to me about issues I ran into.
- Ire Aderinokun for writing an awesome Bits of Code article about how to take a serverless screenshot
- Wes Bos for code examples on how to use local Chrome and talking through image caching with me on Twitter
- Chris Biscardi for this free Egghead series on generating images, using the Cloudinary API, and using redirects and giving me advice on how to point to the correct domain for my functions
- Darrik Moberg and Jason Lengstorf for code examples and helping me debug on Discord